Last Update Date: 3 August 2025
Average Read Time: 9 minutes
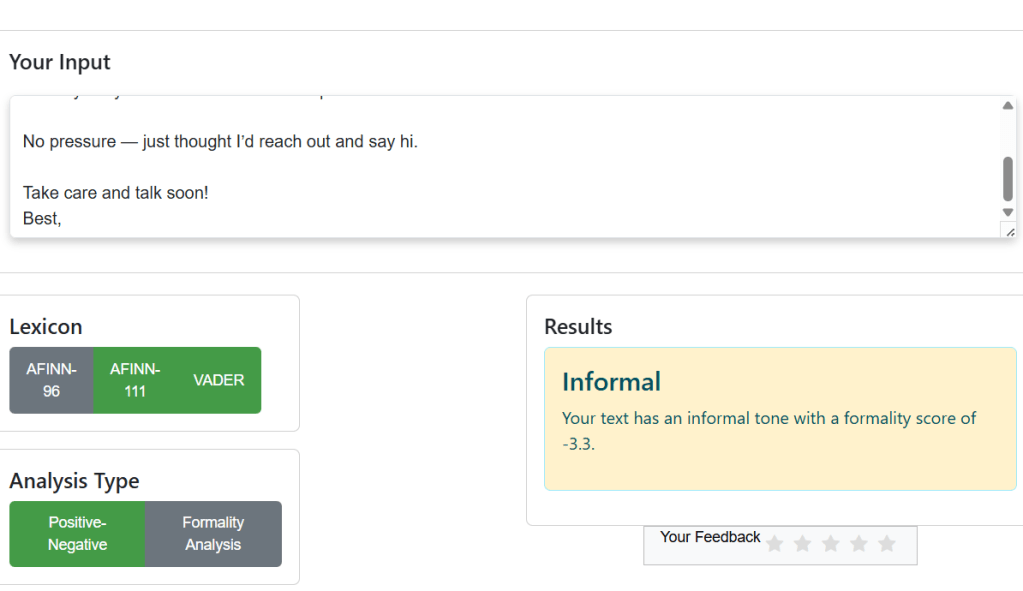
You can try the demo of sentiment analyzer HERE.
Implementation of a Lightweight and Efficient Text Sentiment Analyzer
I am happy to present a simple Flask based web-application for analysis of sentiment of text. This application is very useful for fast and surface level sentiment analysis of e-mails, passages and paragraphs. One of main reasons for developing this web application is to demonstrate that even basic and lightweight machine learning models can perform quite well for certain tasks without need to load and finetune LLMs that usually require either expensive hardware or API subscription to utilize. The light-weight application has 2 main functionalities as of July 2025: performing a sentiment analysis of the text by its polarity (whether the text conveys positive or negative sentiment) using a lexicon-based approach utilizing lexicons like VADER and AFINN and performing an analysis of the formality level of a given text and highlighting the words with colour that changes its hue based on their contribution to the final formality assessment. The formality score is calculated based on bidirectional LSTM that was trained on the ENRON mail dataset. Because lexicon based models don’t require any training procedure, we discussed training pipeline only for the BiLSTM based formality classifier. A manual labelling procedure was called for since ENRON dataset that is used to train the formality classifier doesn’t include labels for formality. 3 independent labellers made sure that the annotations for the samples in the training set are as objective as possible.
Dataset Description, Preparation and Labelling
Dataset Overview
The training set is based on the publicly available ENRON email corpus. The corpus contains over 500,000 emails belonging to the ENRON company prior to its collapse in 2001. This corpus is the most widely used dataset in email research in natural language processing studies because of its authenticity as a source of patterns in relation to corporate communication.(informality) were included in the partitions. For each partition mails were selected so that there is diversity in content and balance between classes ‘formal’ and ‘informal’. Emails that contained only links, contained spam and contained a majority of numerical/graphical content were excluded from the partition selection process.
Annotation Methodology
Since it was not feasible to label the entire corpus, we followed a systematic sampling approach. We utilized 10 balanced splits of 150 messages each, resulting in a total dataset of 1,500 labeled messages. Three human annotators individually evaluated each message and lab-eled it as either ‘formal’ or ‘informal.’ To ensure quality annotations, emails with inter-annotator disagreements went through extra consensus-building sessions in which the ultimate tag was resolved through joint scrutiny. Our sampling ensured variance in levels of formality while maintaining balanced class distribution across every partition. We rejected systematically emails that contained predominantly links, spam messages, or numerical/graphical content to focus on meaningful text communication.
Data Preprocessing
The first email corpus presented significant training challenges due to the prevalence of threaded conversations with multiple messages and varying levels of formality. Threaded conversations in emails create ambiguous supervision signals since machine learning methods require single ground-truth labels per training instance. Separate messages in a thread can have unique formality features, which might confuse the model at training time.
To counter this challenge, we subjected preprocessing to eliminate individual messages with uniform formality patterns. This removes noise induced by mixed-formality threads and provides cleaner and more reliable training signals to the bidirectional LSTM model. By focusing on individual messages rather than entire conversation threads, we enhanced the model’s ability to learn standalone formality features and patterns. The main preprocessing steps are the following:
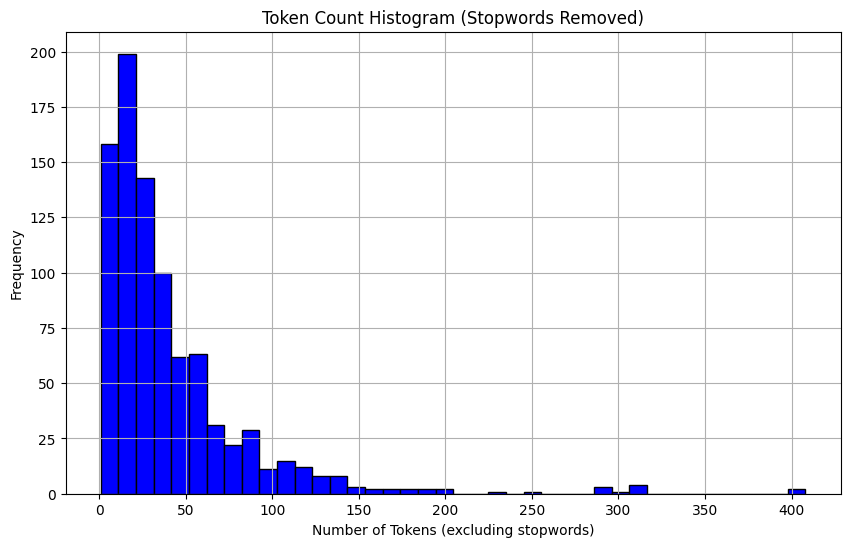
- Tokenization of the input: nltk word_tokenizer was used to split the user input into tokens.
- Removing the stopwords: Common English stopwords were removed.
- Embedding each token with word2vec: glove-twitter-25 embedding model was used to convert each token into a 25-dimensional vector. User inputs were clipped to contain at most 100 tokens.
Since our aim is to develop a lightweight model and we don’t have huge amount of data at our disposal, a relatively simple embedding model with 25 dimensional embeddings was used instead of more complex and heavy embedding models with 200 or more dimensional embedding vectors.
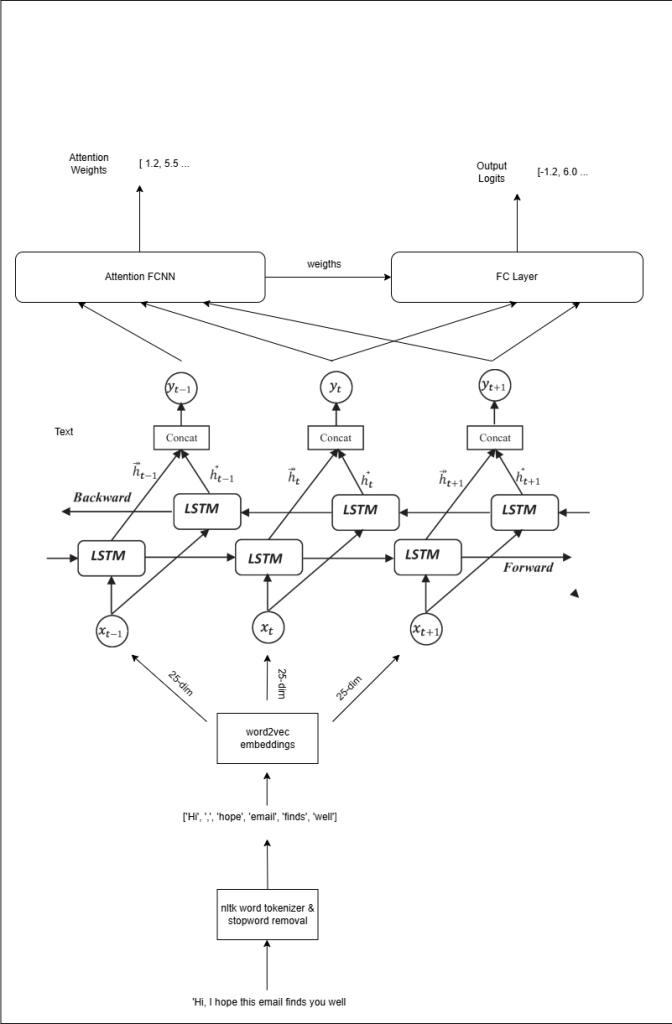
Model Design
Our formality classifier combines bidirectional LSTM processing with attention mechanisms to deliver both accurate predictions and interpretable results. The bidirectional architecture captures contextual relationships from both directions in the text, while the attention mechanism identifies which specific words most strongly indicate formal or informal language. This design philosophy prioritizes interpretability alongside performance. Users receive not only formality scores but also visual feedback highlighting the words that most influenced the prediction. The attention weights enable the application to color-code text based on each word’s contribution to the overall formality assessment. The architecture represents a lightweight alternative to large language models, achieving strong performance with significantly lower computational requirements.
Polarity Prediction and Classification
In the current version of the model, lexicon based methods are used to detect the polarity of the text. Lexicon based methods are one of the most primitive polarity detection methods in NLP. The high-level idea is to classify a texts sentiment based on the words it contains without any consideration of the word ordering or word pairing. 3 different lexicon based methods were used: AFINN96, AFINN 111 and VADER. All of these 3 methods shared same fundamental pipeline to determine the polarity of a text:
- Tokenize the text into words.
- Look each word up in the lexicon to find the corresponding score for each of these words.
- From all of the scores calculate the compund score and determine the sentiment of the text directly from that compound score.
One of the biggest upsides of using these lexicon based techniques is that they do not require any training and are extremely easy to set up for use and straightforward to interpret. Obviously they lack any sophistication in their detection ability and can be used only to get a very crude idea of the polarity of the text. We tried to preserves the interpretability and lightweightness when developing formality detectors while using modern deep learning methods to make predictions much more accurate than lexicon methods. A similar deep-learning based light-weight approach is planned for polarity detection task in the future releases.
Testing the Formality Classifier
To test the performance of the sentiment classification 200 emails, each approximately 50 words long, were generated by Claude 4.0 Sonnet. Half of these emails were formal and the other half was informal. Mails from each class had different degrees of formalities to test the ability of the model to deal with formalities of different degrees. Additionally, a variability of the content among the samples was ensured to allow better coverage of the test set.
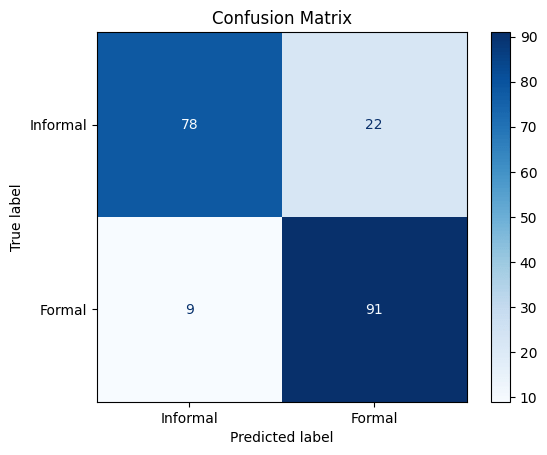
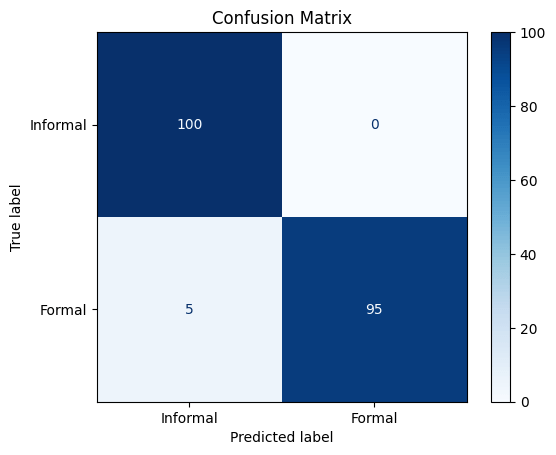

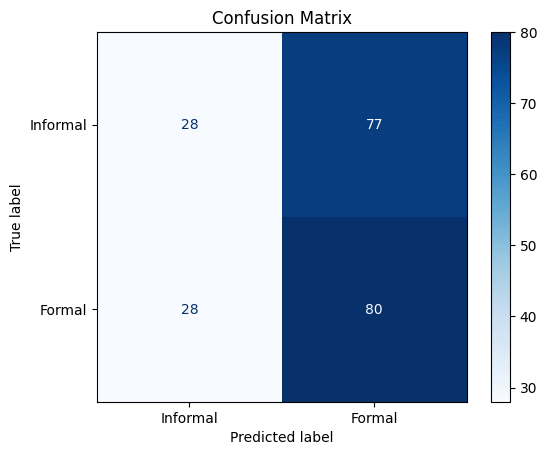
The test results for the test set that contained 50 word mails on average tell us that the model has 84.5 percent accuracy that can be considered pretty good. The recall with 91 percent is better that than precision that is 0.805. With the assumption that the formal mail are labelled as 1, these numbers suggest that the model has a slightly better performance in recognizing formal emails correctly than informal ones. The logit distribution graph of the samples from both of the classes reveals this difference a little bit more: the distribution of the logits for the formal emails has a lower deviation around the peak thus a smaller percentage of formal emails are assigned a logit below 0 (predicted as informal).
Deployment and Integration
The model inference is implemented entirely in Python. API Gateway is configured to expose the Lambda function as a RESTful API endpoint, enabling external clients to send HTTP requests to the model service. The entire backend is dockerized and pushed into ECR (Elastic Container Registry). The frontend sends HTTP requests the RESTful API endpoint and triggers an event for the Lambda function. The lambda function uses the lambda handler to interface between the event and the backend code from the docker image.
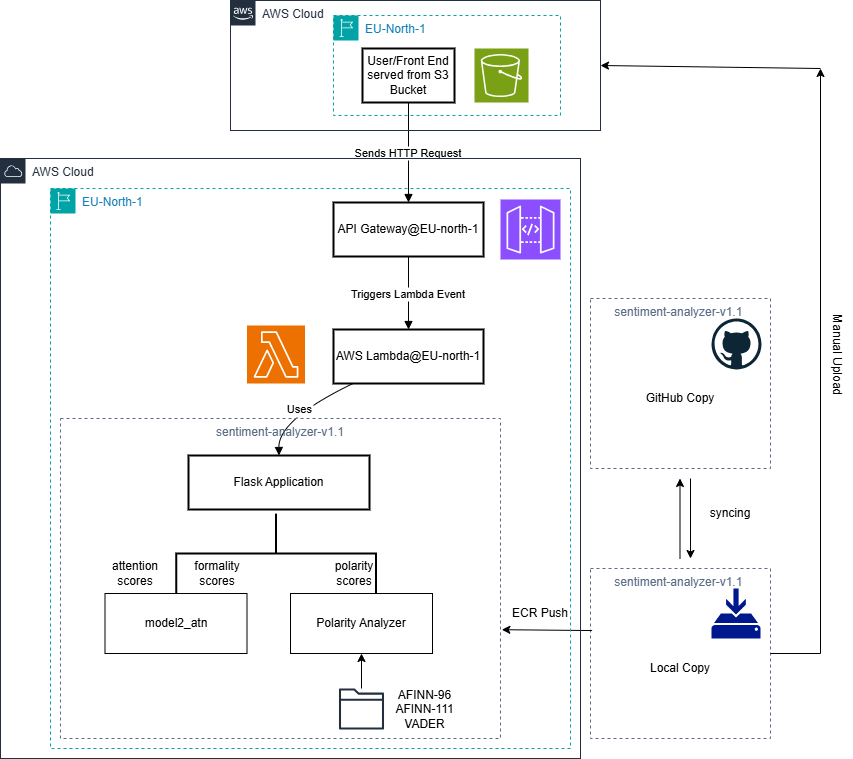
Because the frontend receives the model predictions from the exposed endpoint outside of its origin, the response generated by Lambda function should contain appropriate CORS headers. Otherwise the responses coming from the REST API will be blocked by default by the browser as a part of security policy.
The HTTP request sent from frontend travels through the public internet before reaching the publicly exposed REST API. For obvious security reasons in the future implementations a scheme where the request doesn’t leave the AWS internal network will be implemented.

Other Technical Considerations and Edge Case Evaluation
For now application is only available through browser. In future releases we plan to provide an API access. The robustness and ability of the application to serve big amount of users isn’t tested yet so only personal usage is advised.
To better demonstrate the ability of the formality classifier to handle edge cases, we generated various sentence lists of 100 50-word sentences having following properties that aim to test the robustness of the sentiment classifier handling ambigious and confusing text:
- Formal sentences that are formal despite some words that can be also used in informal contexts.
- Informal sentences that are written in formal language but carry sarcastic tone so are informal in reality.
- Sentences with any other confusion structure that can confuse the model to make erroneous predictions.
Claude 4.0 was prompted to create 100 formal and 100 informal sentences having properties that are mentioned above. The results show us the model is still good at detection formal sentences with confusing structure but the model fails at detecting the sarcasm in sentences with formal wording – it classifies them as formal despite sarcastic tone. This marks one of the weak points of the current model, and future attempts shall make model more robust to sarcasm.
Areas to Improve and Planned Features
- User star-rating system: A feedback mechanism where users can rate the assesments made by the application is planned for future versions. This can reveal not only the content on which the model gave the least satisfactory performance but also ways to finetune and improve the user satisfaction.
- More sentiment types, multimodal capabilities: New sentiment analysis types and multimodal capabilities are planned for future releases.
